Ursa Labs Technology
Technical Vision Documents
Early in 2019, we discussed several significant design documents that articulate the motivation and requirements for our past and future efforts:
Obviously not all of this work has been completed yet, but we have been busy breaking down the projects into tractable pieces and getting them done.
A common question we get is about the relationship between the “data frame” and “query engine” subprojects. Here is the answer:
- Data frames provide a convenient way to execute analytical operations on in-memory (or memory-mapped / out-of-core) datasets. Some algorithms, such as those requiring random access to any row in a table, only make sense in a data frame API.
- The query engine (as proposed) operates on general streams of Arrow data, so can perform aggregations, joins, and other structured data processing with limited memory use. As a limitation, the kinds of analytics supported will be more limited to the domain of SQL. The implementation of many operations (such as aggregations and many group-by operations) can be reused in the data frame API.
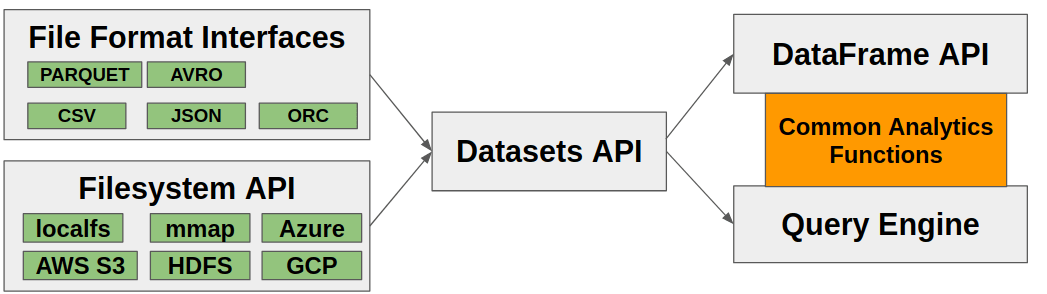
In addition to building this essential functionality in C++, we are building rich bindings in Python and R with integrations into key projects in those ecosystems. Our intent is to accelerate existing data processing work, unlocking new workflows (such as new file formats or larger scale analysis), and generally providing a strong foundation for the next generation of analytics for data scientists.
2020 Outlook and Development Roadmap
We are continuing to pursue the development agenda described in the design documents and working to deepen our integrations with Python and R libraries.
- Datasets API: We will expand to support all of the file formats for which there is an Arrow-based interface. We will also enable writing datasets instead of only reading them. Deeper support for cloud filesystems (and filesystems beyond Amazon S3) is also a priority.
- Kernels and Query Engine Components: Expand our suite of Arrow-native compute functions. Implement some essential query engine components such as hash aggregation, projection, and sorting.
- C++ DataFrame API: We plan to develop an initial alpha version of this API to work in tandem with the compute kernel development. As stated above, the DataFrame API provides a convenience API for evaluating analytical operations against in-memory datasets.
- Multithreading improvements: Apache Arrow in C++ needs to move beyond simple thread pools to manage granular computation tasks and asynchronous IO operations performed by different steps in an in-memory data pipeline. We will work with the community to develop a more forward looking solution to parallel task execution.
- C API / Data Interface: We are developing a C-based data interface to make it easier for third party systems to exchange Arrow data at C call sites without taking on any additional code dependencies. We believe this will simplify Arrow adoption in a number of different settings. The Arrow community has reached consensus about this and we are working to adopt it formally and commit the initial implementation.
- Parquet improvements: We plan to work with the community to enable complete support for reading and writing nested data types. This has been a notable gap in existing Parquet functionality that is important to have filled.
- Benchmark Dashboard: given the amount of performance-sensitive code that we are writing, we intend to develop tooling to begin collecting benchmark outputs from multiple programming languages with the goal of tracking performance over time and on different kinds of hardware configurations and architectures (e.g. both x86 and ARM). This will be increasingly important to prevent performance regressions in the software.