Since launching Ursa Labs in 2018, we have made extraordinary progress growing the Apache Arrow project and supporting the open source community around it. As I explained in my announcement of the initiative, our objective has been to create a robust engineering team in partnership with a wide variety of sponsoring companies with the Arrow project’s success as our number one priority. Since then, we have added NVIDIA, Intel, Bloomberg, G-Research, and OneSixtyTwo Technologies (and some others we cannot name publicly) to our sponsor ranks, joining our founding sponsors RStudio and Two Sigma.
From the perspective of funding the growth and maintenance of an open source project, Ursa Labs has undoubtedly been a success. This level of sponsorship enabled us to add Neal Richardson to the team’s leadership to advance Arrow development for R users, and together we have expanded the Ursa team to six people overall. Together we’ve helped drive the project to its pivotal 1.0.0 release, which is the first formally “stable” release. Working with Dremio and Two Sigma, we have developed Arrow Flight, a state-of-the-art Arrow-native data transport framework. Overall, our team has been responsible for a significant share of the work on the Arrow project:
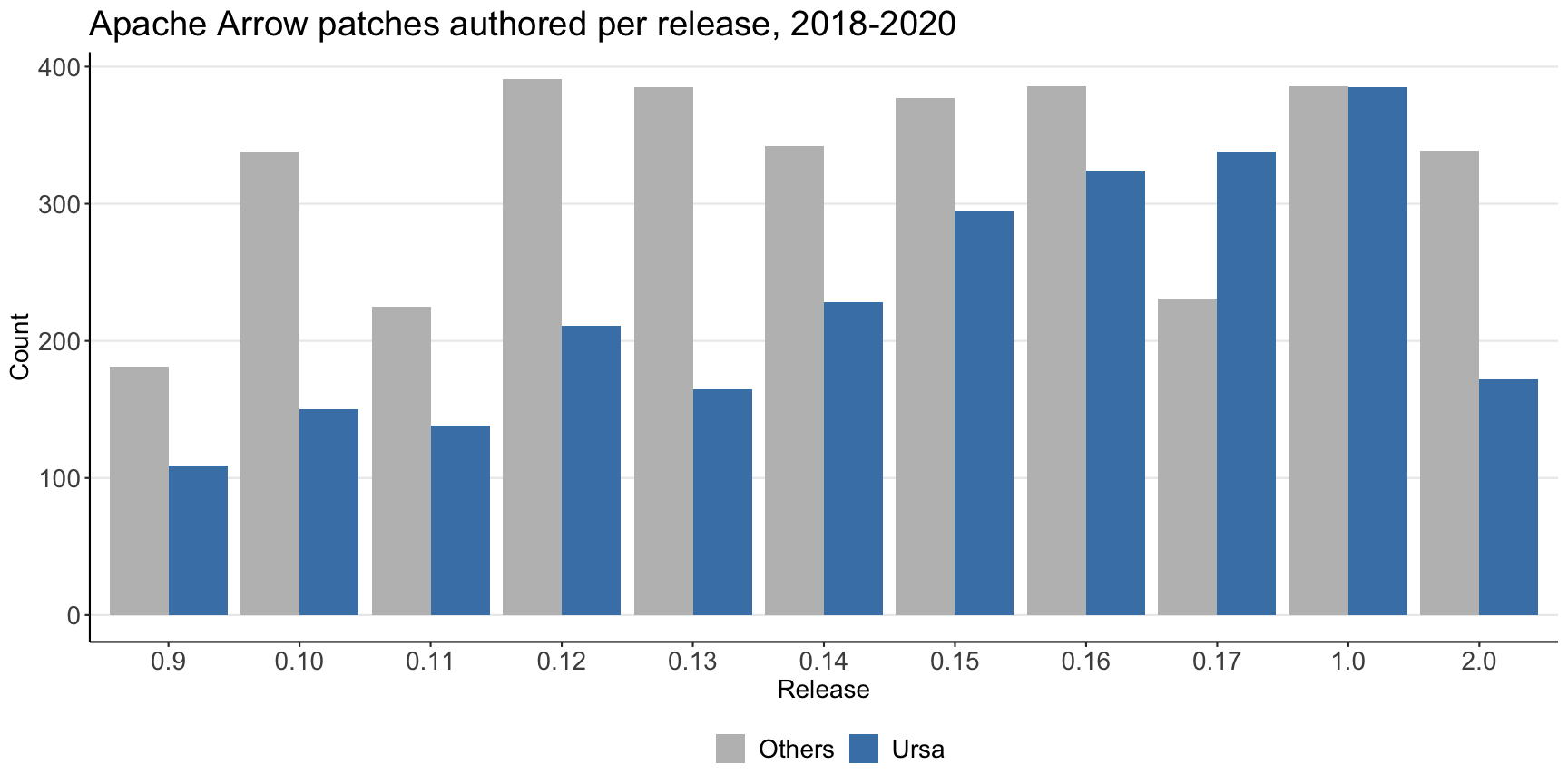
Arrow has quickly become the gold standard for high performance data transfer and data access for data frame-like data. We have seen extraordinary adoption in all kinds of data systems, from computing frameworks like Apache Spark and TensorFlow to data warehouses like BigQuery and Snowflake. At the same time, we are seeing progress on new Arrow-native computing frameworks inside the Apache Arrow project and in both academia and industry.
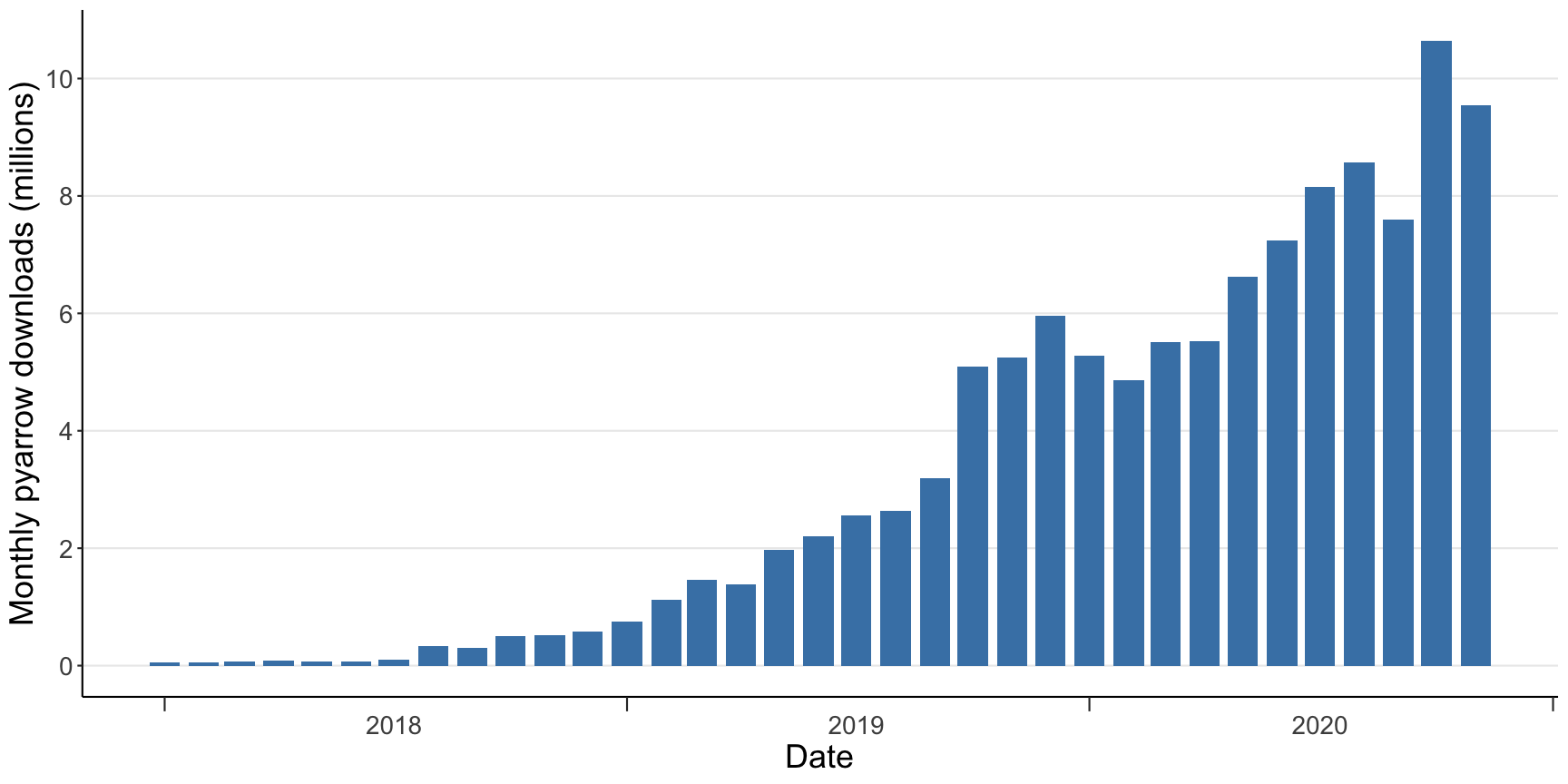
In the Arrow Python package alone, we’ve exceeded 10 million monthly installs as we have become a critical dependency of data processing systems:
Looking ahead
As the Arrow developer and user communities have grown, it has become evident that we need to scale up the Ursa team to sustain the acceleration of ambitious and mission-critical applications based on Arrow. Enterprises are increasingly looking for professional help unlocking the full value that can be achieved by broadly adopting Arrow as the universal standard for fast, serialization-free data access and high performance in-memory analytics on tabular data. While we have created a solid foundation that has improved the lives of data scientists significantly in many ways, we have a lot more to do, and it is essential that we have the engineering personnel and financial resources to be able to realize the vision of an Arrow-native world.
With these things in context, I am excited to announce that we have formed a new company, Ursa Computing, to create enterprise products and services to empower data teams and accelerate data science, machine learning, and AI work. To get this new company off the ground, we have raised $4.9 million in seed funding led by GV, with participation from Walden International, Nepenthe, Amplify Partners, RStudio, and many amazing angel investors.
As I noted in the 2018 announcement, I originally founded Ursa Labs as a non-profit entity, in part to avoid the conflicts that sometimes arise with building a new open source project community while also building a profitable company. With that insulation, Ursa Labs has been successful in cultivating a strong community-centric foundation, and Apache Arrow has reached broad industry adoption and gained a robust developer community.
We see Ursa Computing as a path to invest even more in the open-source community. Working more closely with enterprises to enhance their data platforms will allow us to learn more about how the Arrow project needs to evolve to meet current and future needs. We want to create a “virtuous cycle” where the company’s success enables us to invest more and more in the open source ecosystem. Offering products and services related to Arrow will allow us to tackle problems, such as managed cloud services, that would be challenging to pursue as an open source project; we have seen this pattern play out in many other open source data infrastructure projects.
Over the last five years of Arrow development, we have observed many ways in which data scientists and data engineers are underserved by their computing tools, particularly when it comes to scaling up on big machines or scaling out on large clusters. Python and R users, for example, have often felt like second-class citizens due to costly data interoperability or limited extensibility. The promise of Arrow-native computing platforms is that they can become truly language-agnostic: any programming language that “speaks Arrow” can become a first-class citizen. We believe that current generation large-scale analytics systems which are only “native” to a specific programming language ecosystem (like Java or Scala) will be replaced by more language-agnostic Arrow-based systems. Ursa Computing intends to spearhead this computing revolution.
Since we have grown a team of seasoned Arrow maintainers, it is also incumbent upon us to continue in our leadership of the Apache project. As such, Ursa Computing will maintain a “Labs” team, initially formed by the existing Ursa Labs team, that is primarily focused on advancing and supporting the Arrow open source project. We will continue to accept Labs sponsorships with corporations that wish to directly fund Arrow development and maintenance, and we will be fully transparent with sponsors about how their funds are being directed toward open source work.
We stand at an exciting crossroads with Apache Arrow poised to be the key computational technology powering the future of data science and ML/AI tools. We look forward to working with engineering and data science teams to enable organizations to get more out of their data.