2020 in Apache Arrow development has gotten off to a running start with a 0.16.0 major release around the corner and a 1.0.0 release (including protocol stability guarantees) coming with luck in the first half of the year.
In this blog post, we would like to summarize Ursa Labs development highlights from 2019 and highlight our major focus areas and priorities for 2020. Apache Arrow libraries provide an efficient and high performance development platform that addresses, broadly speaking:
- Storage and deserialization to different file formats
- Fast data transport (i.e. Arrow Flight)
- Fast in-memory processing
We are excited to be working with the open source community to build out this platform to accelerate existing analytical tools as well as to be a foundation for next-generation tools. This includes data frame libraries as well as any system that works with tabular datasets and may need to evaluate analytical queries.
People often ask us how Apache Arrow is doing as an open source project. It’s doing extremely well. After 4 years, we have exceeded 400 unique contributors and adding more every month:
The rate of installs has also grown at a large rate, with 5-6 million installs per month alone from “pip install pyarrow” (for comparison, pandas recently had 16 million downloads in a single month via PyPI). Apache Arrow is available through many other package managers and for many programming languages other than Python.
Our Mission
We founded Ursa Labs with the goal of helping make Apache Arrow a robust and reliable next-generation computational foundation for in-memory analytics and data science. We recognized that existing popular tools such as pandas and base R have fallen short in terms of computational performance and memory use, particularly in the context of modern CPUs, GPUs, and solid state drives.
We believe that a community-led open governance approach in the Apache Software Foundation and a not-for-profit, industry consortium-type funding model is the best way to pursue this development work and place the needs of the open source community first. We also wanted to be free of the potentially distracting influence of venture capital or consulting services.
While working to build a large development community in an Apache project can seem like a lot of work (and we go out of our way to support the growth of the community), we believe that a large, active contributor base coupled with open and transparent governance will yield an open source project with a long lifespan (on the order of decades) and high real world impact.
Technical Vision Documents
Early in 2019, we discussed several significant design documents that articulate the motivation and requirements for our past and future efforts:
Obviously not all of this work has been completed yet, but we have been busy breaking down the projects into tractable pieces and getting them done.
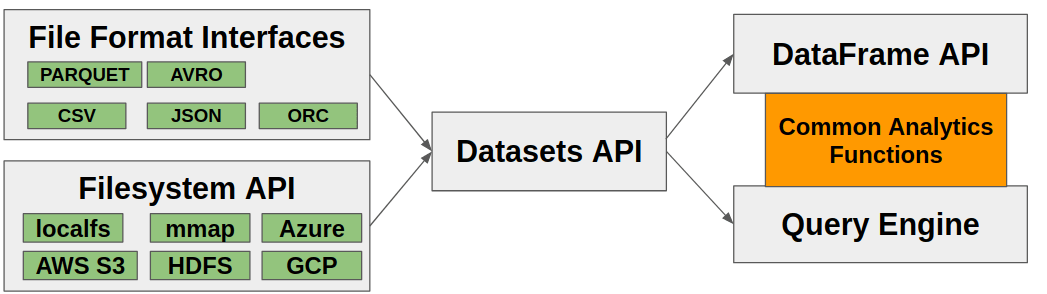
A common question we get is about the relationship between the “data frame” and “query engine” subprojects. Here is the answer:
- Data frames provide a convenient way to execute analytical operations on in-memory (or memory-mapped / out-of-core) datasets. Some algorithms, such as those requiring random access to any row in a table, only make sense in a data frame API.
- The query engine (as proposed) operates on general streams of Arrow data, so can perform aggregations, joins, and other structured data processing with limited memory use. As a limitation, the kinds of analytics supported will be more limited to the domain of SQL. The implementation of many operations (such as aggregations and many group-by operations) can be reused in the data frame API.
In addition to building this essential functionality in C++, we are building rich bindings in Python and R with integrations into key projects in those ecosystems. Our intent is to accelerate existing data processing work, unlocking new workflows (such as new file formats or larger scale analysis), and generally providing a strong foundation for the next generation of analytics for data scientists.
Doing all of this work properly in high quality C++ libraries with bindings in multiple languages is time- and labor-intensive, but doing so will yield dividends for open source data tools for many years to come.
Relationship with existing R and Python projects
One of the most common questions we are asked is how users of popular R and Python libraries will be able to take advantage of Apache Arrow. In some cases, such as with dplyr and tidyverse tools in R, we can provide a more natural and seamless integration, while in others (like pandas) it will be more complex. We are working as closely as possible with the respective developer communities to deliver value to end users.
The other way that Arrow is useful is as a dependency in other projects, augmenting their capabilities without the end user necessarily knowing that they’re using Arrow. In Python, pyarrow is already being used in many downstream projects for various use cases, including:
- Dask, for Parquet support
- Google BigQuery Python API, for data ingest
- pandas, for Parquet support
- PySpark, for UDF evaluation and data interchange
- Ray, for general serialization and messaging
Similarly, the arrow R package can be used to accelerate data transfer with Spark in the sparklyr package.
2019 Development Highlights
At the beginning of last year, we started publishing periodic status reports to summarize the work we are doing in Apache on a month-to-month basis. As we have settled into a groove, we have found that status reports every two to three months feels like a good cadence and doesn’t create too much overhead for us. You can find our 2019 reports here:
Some of the most significant milestones from 2019 include:
- R bindings development and CRAN release: In August 2019, we made the
first release of Apache Arrow on the CRAN package repository. This was a
large effort that involved a lot of R-specific packaging work to enable
installation on Linux, macOS, and Windows. We have most recently been
working to make the installation process more seamless on Linux. While past
releases required first installing the Arrow C++ library using a Linux
package manager like
aptoryum, the 0.16 release does not require external system dependencies. - Arrow Flight: We have collaborated over the last 2 years with Dremio and our sponsor Two Sigma to create Arrow Flight, a framework for building high performance data services. We are very excited about this as it makes it easy to use Arrow for faster data transport in distributed systems, blowing away legacy data protocols that are bogged down by serialization overhead.
- Filesystems API and S3 support: In C++ we developed a standardized filesystem API to tie together local and remove raw file storage with a common interface. This is an essential dependency of the Datasets API and therefore transitively of the compute APIs.
- Datasets API: in August we launched this development effort to provide efficient access to large datasets consisting potentially of multiple files, file formats, or storage backends. This includes intelligent schema projections and row filtering. We are designing this API to be suitable to support streaming analytics as well as fully in-memory data frame-style analytics.
- GitHub Actions for Continuous Integration (CI): As the project has grown in size and number of active developers, we found ourselves dragged down by long build queues on Travis CI and Appveyor. In August 2019, GitHub announced their new integrated CI offering GitHub Actions, and have provided ample compute firepower to the Apache Software Foundation. Krisztián Szűcs led a mass migration of almost all of our CI tasks to use GitHub Actions, and we are very happy with the results.
- Apache Parquet improvements: in addition to improving Parquet performance and memory use, we worked to enable deeper integration with Apache Arrow’s dictionary-encoded data types.
Aside from some of these specific feature areas, we have also made significant improvements across the project to improve developer productivity and accessibility to new contributors.
2020 Outlook and Development Roadmap
This year we are continuing to pursue the development agenda described in the design documents referenced above and working to deepen our integrations with Python and R libraries.
- Datasets API: We will expand to support all of the file formats for which there is an Arrow-based interface. We will also enable writing datasets instead of only reading them. Deeper support for cloud filesystems (and filesystems beyond Amazon S3) is also a priority.
- Kernels and Query Engine Components: Expand our suite of Arrow-native compute functions. Implement some essential query engine components such as hash aggregation, projection, and sorting.
- C++ DataFrame API: We plan to develop an initial alpha version of this API to work in tandem with the compute kernel development. As stated above, the DataFrame API provides a convenience API for evaluating analytical operations against in-memory datasets.
- Multithreading improvements: Apache Arrow in C++ needs to move beyond simple thread pools to manage granular computation tasks and asynchronous IO operations performed by different steps in an in-memory data pipeline. We will work with the community to develop a more forward looking solution to parallel task execution.
- C API / Data Interface: We are developing a C-based data interface to make it easier for third party systems to exchange Arrow data at C call sites without taking on any additional code dependencies. We believe this will simplify Arrow adoption in a number of different settings. The Arrow community has reached consensus about this and we are working to adopt it formally and commit the initial implementation.
- Parquet improvements: We plan to work with the community to enable complete support for reading and writing nested data types. This has been a notable gap in existing Parquet functionality that is important to have filled.
- Benchmark Dashboard: given the amount of performance-sensitive code that we are writing, we intend to develop tooling to begin collecting benchmark outputs from multiple programming languages with the goal of tracking performance over time and on different kinds of hardware configurations and architectures (e.g. both x86 and ARM). This will be increasingly important to prevent performance regressions in the software.
Summary
We have laid out an ambitious development roadmap before us, but we are building essential open source computational software that will be widely deployed and used for many years. Much of the proverbial “low-hanging fruit” in data science tools has already been picked, and building faster, more efficient software to accelerate current work is much more difficult and time consuming than building the last generation of open source tools.
As Ursa Labs depends on the generosity of its corporate sponsors, one of the ways that you can help us make faster progress and expand the scope of our work is by becoming a sponsor. If you would like to discuss this with us, please read more on our website or reach out to info@ursalabs.org.
We’d like to thank our current 2020 sponsors and look forward to the year ahead:
- RStudio (our largest sponsor and administrative partner)
- Two Sigma
- Intel
- NVIDIA
- Bloomberg
- G-Research
- OneSixtyTwo Technologies